Few-Shot, Vision-Only ICL
A compact transformer that classifies images in-context using only visual embeddings — no gradient updates, no language supervision. Strong out-of-domain performance depends critically on how the embedding model is pretrained.

Fresh notes & findings from the team.
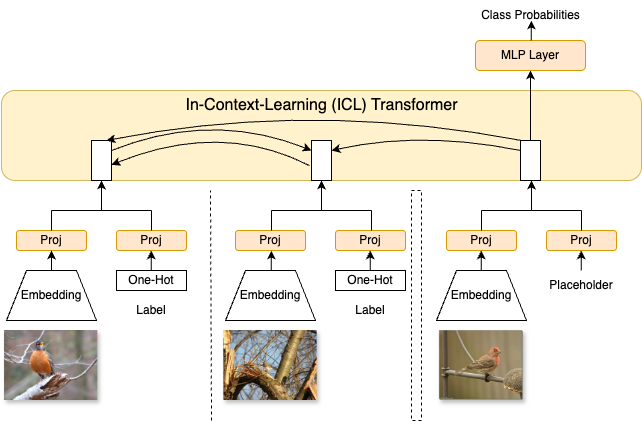
Sequence of support tokens (image + label) and a query token enter a 4-block Transformer encoder with asymmetric attention: support attends to support; query attends to all support; support does not attend to query. The query representation feeds a classification head to predict the label.
Details in the paper.
from PictSure import PictSure
from PIL import Image
model = PictSure.from_pretrained("pictsure/pictsure-vit")
context_images = [
Image.open("cat1.jpg"),
Image.open("cat2.jpg"),
Image.open("dog1.jpg"),
Image.open("dog2.jpg")
]
context_labels = [0, 0, 1, 1]
model.set_context_images(context_images, context_labels)
test_image = Image.open("unknown_animal.jpg")
prediction = model.predict(test_image)
print(f"Predicted class: {prediction}")
All PictSure models and inference code are fully open source and available for use and modification. The training script will be released soon.
Each model differs only in the embedding backbone and pretraining method; all share the same ICL transformer and label-in-token design.
Hugging Face Models GitHub Repository